Energy-Based Transformer―AIが自らの文章を「吟味」する新技術―
2025/08/05 AI JEPA Transformer 計算複雑性理論
この記事のまとめ
- 概要: 大規模言語モデル(LLM)の「生成能力」とエネルギーベースモデル(EBM)の「判断能力」を融合させた新しいAIアーキテクチャです。
- 自己評価と修正: 生成した文章が論理的かを"エネルギー"という指標で自己評価し、質の高い文章になるよう修正しながら生成を進めることで、ハルシネーション(事実誤認)を抑制します。
- 設計思想の背景: 人間の「直感(システム1)」と「理性(システム2)」の思考プロセスや、「問題を解くより検証する方が簡単」という計算複雑性理論の考えに基づいています。
はじめに:LLMの次なる進化 - 「生成」から「吟味」へ
GPTやGeminiといった大規模言語モデル(LLM)は、驚くほど流暢な文章を生成し、私たちの日常に浸透しました。これらのモデルは、膨大なテキストデータを学習することで、「次に来る確率が最も高い単語」を予測する能力を極限まで高めています。
しかし、AI研究の第一人者であるヤン・ルカン氏が指摘するように、現在のLLMは「物理法則を知らないまま物理の教科書を丸暗記した学生」のようなものです。言葉のパターンを模倣するのは得意ですが、その言葉が指し示す世界の仕組みや論理的な整合性を本当に理解しているわけではありません。そのため、時として事実と異なる情報(ハルシネーション)を生成したり、話の辻褄が合わなくなったりする欠点があります。
参考記事: ヤン・ルカンが描く未来のAIこれは、心理学者ダニエル・カーネマンが提唱した「システム1(速い思考)」に似ています。直感的で、深く考えずに、素早く答えを出す思考です。LLMの文章生成も、このシステム1的なプロセスに大きく依存しています。
では、どうすればAIはもっと賢くなれるのでしょうか?私たち人間は、直感で思いついた考えを、じっくりと論理的に見直す「システム2(遅い思考)」も持っています。AIにも、自ら生成した内容を「吟味」し、その質を評価して修正する、このシステム2的な能力を持たせられないか?
この問いに対する一つの答えが、今回ご紹介する「Energy-Based Transformer (EBT)」です。
Energy-Based Transformerの核心思想
エネルギーで「良し悪し」を測る
EBTを理解するために、まずはその根幹にある「エネルギーベースモデル(EBM)」の考え方を復習しましょう。
エネルギーベースモデル(EBM)再訪
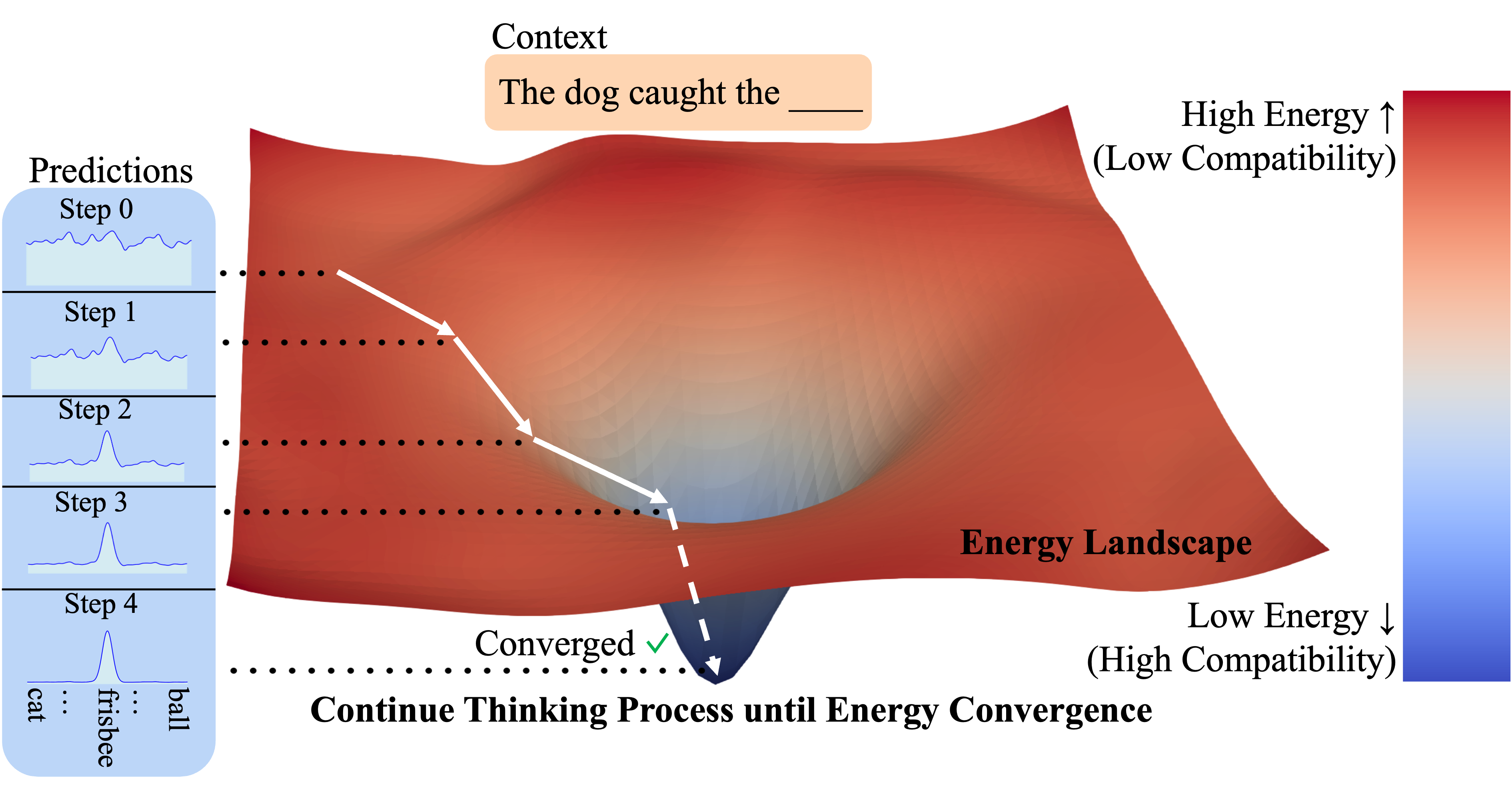
- エネルギーランドスケープ: 広大な地形図を想像してください。AIにとって「正解」や「あり得る状態」は、エネルギーが低い「谷底」にあります。逆に、「間違い」や「あり得ない状態」は、エネルギーが高い「山」にあります。
- 学習の目的: AIの学習とは、この地形図上で、正しいデータが「谷底」に、間違ったデータが「山」に配置されるように、地形そのものを形作っていくプロセスです。
このEBMを使うと、あるデータがどれくらい「もっともらしいか」を一つの数値(エネルギー値)として評価できます。エネルギーが低いほど、そのデータは質が高いと判断できるわけです。
Transformerとの融合:生成器と評価器のタッグ
EBTは、このEBMの「評価能力」と、従来のTransformerが持つ「生成能力」を組み合わせたものです。
- Transformer(生成器): 「次に来る単語の確率」を予測し、文章を組み立てていきます。
- エネルギー関数(評価器): 生成された文章を受け取り、その文章全体の「エネルギー(質の低さ)」を計算します。
GladstoneらのEnergy-Based Transformerの設計とアーキテクチャ
設計思想1:問題を解くより、検証する方が簡単
計算複雑性理論の「NPクラス」の考え方はLLMにも当てはまります。「解を見つけるのは難しくても、解が正しいか検証するのは比較的簡単」というものです。EBTは、この「生成と検証」のサイクルをモデル内部に組み込むことで、難しい「生成」タスクを、より簡単な「検証」タスクでガイドします。
参考記事: o1モデルと計算複雑性理論と軽量化の方法設計思想2:AIにおける「システム2思考」の実装
EBTの動作は、人間の「システム2思考」を模倣する試みです。
- システム1(直感的思考): ベースとなるTransformerが、次に来る単語の候補を素早く提案します。
- システム2(熟考的思考): エネルギー関数が、それらの候補を繋げた場合の文章全体の質をじっくり評価し、最良の選択を促します。
アーキテクチャと推論プロセス
EBTは、標準的なTransformerである「ベースモデル(生成器)」と、文章の質を評価する「エネルギー関数(評価器)」で構成されます。文章生成は以下のステップで行われます。
- 候補の提案: ベースモデルが次に来る単語の候補をいくつか挙げます。
- 未来のシミュレーション: 各候補を選んだ場合の文章の断片を仮作成します。
- エネルギー評価: エネルギー関数が各断片の「エネルギー(質の低さ)」を計算します。
- 総合評価と選択: ベースモデルの「確率」とエネルギー関数の「エネルギー値」を合算し、最もスコアの高い単語を選択します。

この総合評価は、数式で次のように表すことができます。文脈を $x$、次の単語の候補を $y$ としたとき、その候補のスコアは以下のように計算されます。
- $P_{\text{base}}(y|x)$: ベースモデルが予測する、文脈 $x$ の後に単語 $y$ が来る確率です。
- $E(x, y)$: エネルギー関数が評価する、単語 $y$ を繋げた文章のエネルギー(質の低さ)です。
- $\alpha$: エネルギー関数の評価をどれだけ重視するかを調整する重み係数です。
モデルは、このスコアが最大になる単語を選択します。つまり、ベースモデルからの確率が高く、かつエネルギー関数からの評価が良い(エネルギーが低い)候補が選ばれる仕組みです。
他モデルとの比較
| モデル | 主な目的 | アプローチ | 例えるなら… |
|---|---|---|---|
| 標準LLM (GPTなど) | 流暢なテキスト生成 | 次単語の確率を最大化 | 直感で素早く返事をする人(システム1) |
| JEPA | 賢い世界モデルの構築 | 入力データの抽象的な意味を予測 | 物事の本質を見抜こうとする学習者 |
| Energy-Based Transformer (EBT) | 高品質なテキスト生成 | 生成物のエネルギー(質)を最小化 | 自分の発言を吟味し修正する熟考者(システム2) |
JEPAとの関係
JEPAもエネルギーベースの考え方を用いますが、目的が異なります。JEPAの目的はAIの「入力処理」を洗練させて世界を理解すること、EBTの目的はAIの「出力制御」を洗練させて高品質なテキストを表現することです。
結論:AIは自らの思考を「吟味」する時代へ
Energy-Based Transformerは、LLMの進化における重要な分岐点を示しています。これまでのAIが「いかに流暢に話すか」を追求してきたのに対し、EBTは「いかに内容を吟味し、質の高い思考をするか」という新たな次元に足を踏み入れようとしています。
このアプローチは、AIがより人間に近い「熟考」能力を獲得し、単なる便利な「物知り」から、私たちが本当に信頼できる「賢いパートナー」へと進化していく可能性を秘めています。
計算複雑性理論、心理学、物理学など、異なる分野の知見が融合して次世代のAIアーキテクチャを生み出しているという事実は、非常に刺激的です。EBTの研究はまだ始まったばかりですが、今後のAI開発の方向性を占う上で、間違いなく注目すべき技術と言えるでしょう。