AIの常識を覆す?脳の仕組みに学ぶ新星「階層的推論モデル(HRM)」徹底解説
2025/08/12 AI AI Agent LLM Reasoning Transformer 世界モデル
この記事のまとめ
- 巨大化するAIへのアンチテーゼ: 現在のAI開発は「モデルは大きいほど賢い」という考え方が主流です。しかし、Hierarchical Reasoning Model(HRM)は、巨大なパラメータや膨大な学習データに頼らず、人間の脳の仕組みにヒントを得た、よりスマートで効率的なアプローチを提案しています。
- 「計画役」と「実行役」のチームプレイ: HRMの内部には、戦略を立てる「高レベル(H)モジュール」と、具体的な計算を行う「低レベル(L)モジュール」が存在します。この2つが連携し、人間のように深く、段階的に思考することで、従来のAIが苦手としてきた複雑な推論タスクを解決します。
- 驚異的な「思考力」と「効率」: HRMは、超難解な数独やパズル問題において、現在の主流であるTransformerベースの巨大AIが全く歯が立たない中、圧倒的な正解率を叩き出しました。しかも、それをごくわずかな学習データと計算コストで達成しており、AIの未来を塗り替える可能性を秘めています。
はじめに:AI開発の「常識」は本当に正しいのか?
「AI」と聞いて、多くの人がChatGPTのような大規模言語モデル(LLM)を思い浮かべるでしょう。これらのAIの進化を支えてきたのは、「モデルのパラメータを増やし、インターネット規模の膨大なデータで学習させればさせるほど、AIは賢くなる」という、いわば「力こそパワー」な思想でした。
しかし、このアプローチは、莫大な計算資源(と電力)を必要とし、一部の巨大テック企業しか開発競争に参加できないという課題も生んでいます。
そんな中、「もっと賢いやり方があるはずだ」と、AIのアーキテクチャ(構造)そのものを見直す動きが活発になっています。その最前線に現れたのが、シンガポールの研究企業Sapient Intelligenceが開発した「階層的推論モデル(Hierarchical Reasoning Model, HRM)」です。
HRMは、力任せのスケールアップではなく、私たちの脳が情報を処理する仕組みから着想を得ています。この記事では、AIの新たな可能性を示すHRMが、一体どのような仕組みで、なぜそれほど「賢い」のかを徹底的に解説していきます。
第1部 HRMとは何か? - 脳の叡智をAIに
HRMを理解する上で最も重要なのは、それが「Transformerではない」ということです。では、一体何なのでしょうか?
脳から学んだ2つの重要なヒント
HRMの設計は、計算論的神経科学の知見、特に人間の脳が持つ以下の2つの特徴を模倣しています。
- 階層的処理(Hierarchical Processing): 私たちの脳は、情報を階層的に処理します。例えば、物を見るとき、まず目から入った光の点を認識し(低レベル)、それが線になり、形になり、最終的に「これは猫だ」と概念的に理解します(高レベル)。高次の脳領域ほど、より抽象的で長期的な情報を扱います。
- 時間的分離(Temporal Separation): 脳の各階層は、異なる時間スケールで活動しています。長期的な計画を立てる脳領域はゆっくりと活動し、具体的な手足の動きを制御する領域は素早く活動します。この時間的な役割分担が、安定した思考と迅速な行動を両立させているのです。
HRMの心臓部:「CEO」と「現場チーム」の連携
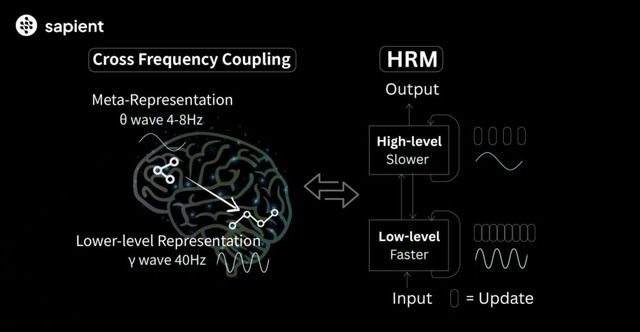
HRMは、この脳の仕組みを「高レベル(H)モジュール」と「低レベル(L)モジュール」という2つのコンポーネントで再現しています。これは、会社組織に例えると非常に分かりやすいです。
Hモジュール(プランナー / CEO)
役割: 問題解決のための全体戦略を立てる「CEO」や「計画立案者」。
動作: ゆっくりとした時間スケールで動作し、抽象的で熟慮的な推論を行います。「まず、パズルの角から埋めていく方針でいこう」といった大枠を決定します。
Lモジュール(エグゼキューター / 現場チーム)
役割: CEOから与えられた戦略に基づき、具体的な計算や試行錯誤を行う「現場チーム」。
動作: 速い時間スケールで動作し、Hモジュールの方針の下で「じゃあ、この角に『5』を置いたらどうなる?」といった具体的な計算を高速で繰り返します。
この2つのモジュールが連携することで、HRMは複雑な問題を「まず全体の方針を立てて、次にその方針に従って細部を詰める」という、人間のような階層的なアプローチで解決していくのです。
第2部 なぜHRMはこれほど「賢い」のか?
HRMの真価は、その驚異的な推論能力にあります。なぜ、巨大なLLMが解けない問題を、はるかに小さなHRMが解けるのでしょうか?その秘密は、主流のTransformerアーキテクチャとの根本的な違いにあります。
違い①:「考える深さ」が違う(可変的計算深度 vs 固定的計算深度)
- Transformer(固定的計算深度): Transformerは、何層ものレイヤーを積み重ねた構造をしています。情報が入力されると、決まった数のレイヤーを一度だけ通過して答えが出力されます。これは、計算の深さが固定的であることを意味します。どんなに難しい問題でも、同じステップ数で考えなければなりません。理論的には、この固定的な深さはTransformerの計算能力に根本的な制約を課しており、多段階のステップを要する複雑なアルゴリズムを解くことが原理的に困難であるとされています。
- HRM(可変的計算深度): HRMはリカレント(再帰的)な構造を持ち、HモジュールとLモジュールの間で計算のサイクルを何度も繰り返すことができます。難しい問題に直面すると、サイクル数を増やして、より深く、より長く考えることができます。これにより、実質的に可変的な計算深度を実現しています。この反復的な計算プロセスこそが、Transformerのアーキテクチャ上の限界を打ち破る鍵なのです。
違い②:「考え方」が違う(潜在空間での推論 vs 思考の連鎖)
- Transformer(思考の連鎖 / Chain-of-Thought): LLMに難しい問題を解かせるとき、「ステップバイステップで考えてください」と指示することがあります。これは「思考の連鎖(CoT)」と呼ばれるテクニックで、AIに思考プロセスを言葉として書き出させることで正解率を上げる手法です。しかし、これは人間で言えば「声に出して考えないと解けない」ようなもので、途中で一つ間違えると、その後のすべてが崩れてしまう脆さも持っています。
- HRM(潜在空間での推論): 一方、HRMは計算のほとんどをモデル内部の「潜在空間」で行います。これは、私たちが頭の中で黙って思考を巡らせるのに似ています。言葉に変換するコストや曖昧さを排除し、より効率的でロバスト(間違いに強い)な推論が可能です。Hモジュールが立てた仮説をLモジュールが内部で検証し、ダメならHモジュールが別の仮説を立て直す、という試行錯誤を高速で行えるのです。
第3部 HRMの思考エンジン:詳細メカニズム
HRMの驚異的な能力は、そのユニークな内部メカニズムから生まれます。ここでは、その思考のエンジンとも言える3つの重要な要素を詳しく見ていきましょう。
1. 階層的収束:深く考えるためのサイクル
標準的なRNN(リカレントニューラルネットワーク)は、計算を繰り返すうちに思考が止まってしまう「早期収束」という弱点がありました。HRMは「階層的収束」という仕組みでこれを克服します。
- Lモジュールの局所的収束: まず、Hモジュールが「この方針でやってみよう」という大まかな計画を立てます。その計画(コンテキスト)の下で、Lモジュールが高速で計算を繰り返し、与えられたサブ問題を解くための「局所的な答え」にたどり着きます。
- Hモジュールの更新: Lモジュールが答えを出すと、その結果がHモジュールにフィードバックされます。「この方針でやったら、こういう結果になった」という報告を受け、Hモジュールは全体戦略を見直し、次の計画を立てます。
- Lモジュールのリセットと再起動: Hモジュールが新たな計画を立てると、Lモジュールは前の計算結果をリセットし、新しい計画の下で再び計算を開始します。
この「Lが計算→Hが計画見直し→Lがリセットして再計算」というサイクルを何度も繰り返すことで、HRMは思考停止に陥ることなく、非常に深いレベルまで問題を掘り下げて考えることができるのです。
2. 適応的計算時間(ACT):脳の「システム1/2」を模倣
HRMは、問題の難しさに応じて「考える時間」を自分で調整する適応的計算時間(Adaptive Computation Time, ACT)という賢い仕組みを持っています。これは、人間の脳の二つの思考モードによく似ています。
- システム1(速い思考): 直感的で素早い判断。簡単な問題に対して、HRMは少ない計算サイクルで素早く答えを出します。
- システム2(遅い思考): 論理的で熟慮的な判断。難しい問題に直面すると、HRMは自ら計算サイクルを増やし、じっくり時間をかけて考えます。
この機能により、HRMは無駄な計算を省き、リソースを効率的に使いながら、難しい問題にも対応できる柔軟性を獲得しています。
3. 効率的な学習:BPTTの回避と驚異のデータ効率
- BPTTの回避: 従来のリカレントモデルは、時間を通じた逆伝播(BPTT)という手法で学習していましたが、これは計算が長くなるほどメモリ消費が増大するという問題がありました。HRMは、計算プロセスを短いセグメントに区切り、セグメントごとに学習を行う賢い方法を採用しています。これにより、勾配が過去にさかのぼりすぎるのを防ぎ、メモリ使用量を一定に保ちながら効率的に学習できます。
- 驚異的なデータ効率: なぜHRMは少ないデータで賢くなれるのでしょうか?それは、その脳に着想を得たアーキテクチャ自体が、問題の根底にある論理やルールを学習するための強力な「帰納バイアス」(学習のヒント)を持っているからです。Transformerが膨大な事例からパターンをかき集めるのに対し、HRMはより少ない例から本質を掴むことができるのです。
第4部 AIの潮流におけるHRMの位置づけ
HRMは、AIアーキテクチャの系譜の中でどのような立ち位置にあるのでしょうか。
- RNNの正統進化形: HRMは、シーケンシャルなデータを扱うのが得意なRNNの進化形と見なせます。RNNが抱えていた「勾配消失」や「早期収束」といった長年の課題を、階層的収束という独創的なアイデアで解決しました。
- Transformerとの関係: HRMは、現在の主流であるTransformerとは根本的に異なるアプローチを取ります。Transformerが巨大な知識と並列処理で「広く浅く」問題を捉えるのに対し、HRMは反復的な計算で「狭く深く」問題を掘り下げます。
- Mambaとの比較: 最近注目されているMambaも、Transformerへの代替案として登場したリカレント系のモデルです。しかし、両者の目的は異なります。
- Mamba: 長い文章や時系列データなど、長距離の文脈を効率的に処理することに特化しています。
- HRM: 複雑なルールに基づいたパズルなど、深い論理的推論を行うことに特化しています。
このように、AIの世界は「Transformer一強」の時代から、それぞれのタスクに特化した多様なアーキテクチャが共存する「カンブリア爆発」の時代へと移行しつつあります。HRMは、その中でも「深い推論」という重要なニッチを担う、極めて有望なプレイヤーなのです。
証拠:ベンチマークが示す圧倒的な性能差
このアーキテクチャの違いが、どれほどの性能差を生むのか。以下の表は、その衝撃的な結果を示しています。
| ベンチマーク | モデル | パラメータ数 | 学習サンプル数 | 正解率 (%) |
|---|---|---|---|---|
| 超難解な数独 (9x9) | HRM | 27M | 1000 | 55.0% |
| GPT-4o (CoT) | ~1.7T? | 事前学習 | 0.0% | |
| Direct pred (Transformer) | 27M | 1000 | 0.0% | |
| 複雑な迷路探索 (30x30) | HRM | 27M | 1000 | 74.5% |
| GPT-4o (CoT) | ~1.7T? | 事前学習 | 0.0% | |
| Direct pred (Transformer) | 27M | 1000 | 0.0% | |
| 抽象推論パズル (ARC-AGI) | HRM | 27M | ~960 | 40.3% |
| GPT-4o (CoT) | ~1.7T? | 事前学習 | ~34% | |
| Direct pred (Transformer) | 27M | ~960 | 21.0% |
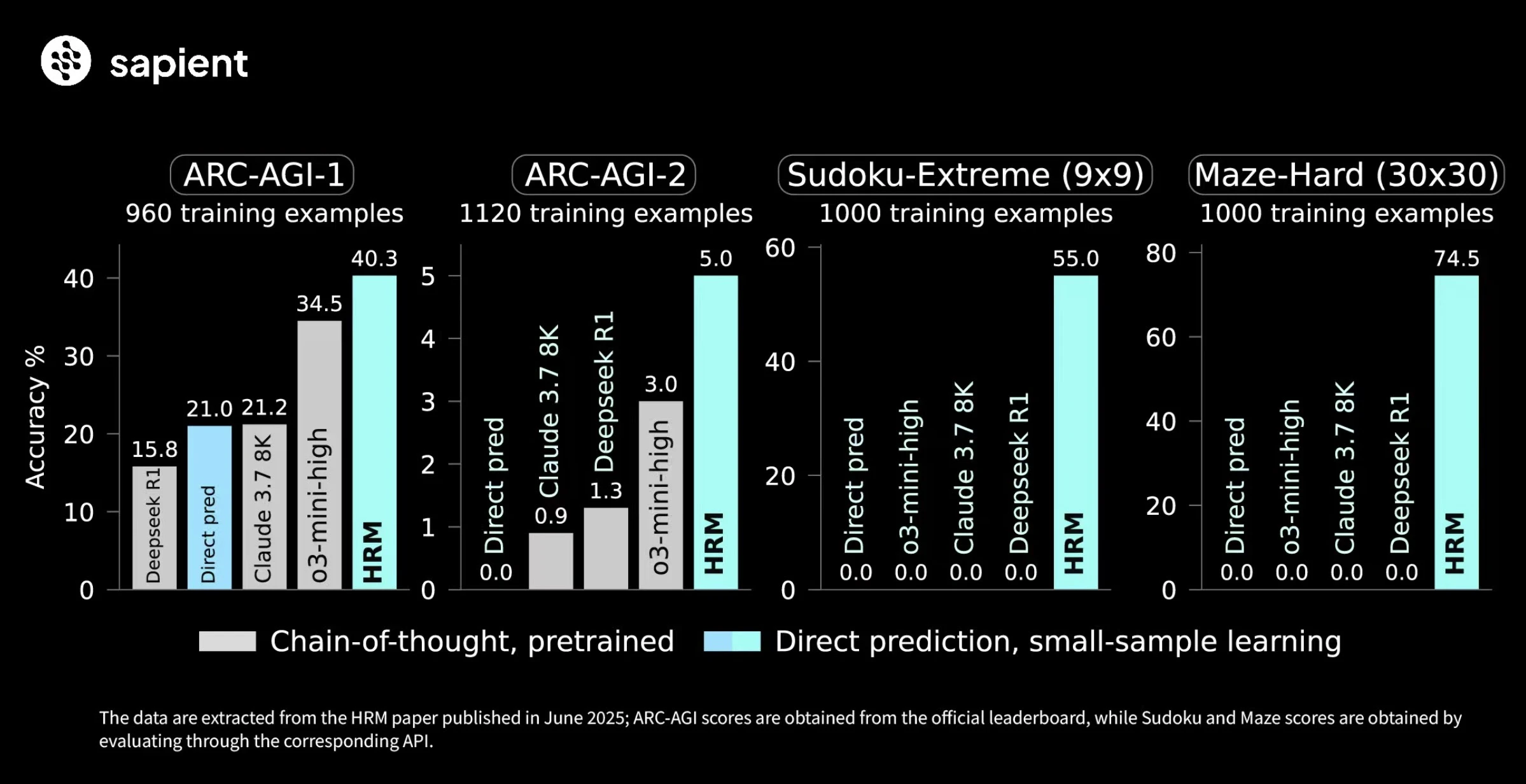
この結果は衝撃的です。数独や迷路のような、厳密なルールに従ってステップを積み重ねる必要があるタスクでは、巨大なLLMでさえ全く正解できませんでした。これは、モデルの大きさや知識量ではなく、Transformerというアーキテクチャ自体が、この種のアルゴリズム的な推論を苦手としていることを示しています。
一方でHRMは、まさにこの種のタスクを解くために設計されたアーキテクチャの力で、圧倒的な性能を発揮しました。これは、AIの能力は、スケールだけでなく、タスクに適したアーキテクチャ設計によって大きく左右されるという強力な証拠です。
おわりに
Hierarchical Reasoning Model(HRM)は、単なる新しいAIモデルではありません。それは、「大きさ」や「力」だけを追求してきたAI開発の潮流に、「賢さとは何か?」という本質的な問いを投げかける存在です。
脳の仕組みに学び、階層的かつ反復的に思考するHRMのアプローチは、より効率的で、堅牢で、そしておそらくは人間にとってより理解しやすいAIへの道を示しています。
もちろん、HRMがAIのすべてを置き換えることはないでしょう。しかし、この小さな挑戦者がAIの世界に投じた一石は、間違いなく、私たちが知るAIの未来をより豊かで多様なものに変えていく大きな波紋となるはずです。