DeepSeekの技術解説: Part 1 - Mixture of ExpertsとMulti-head Latent Attention
2025/04/03 AI Attention DeepSeek LLM MoE Transformer
はじめに
近年、人工知能(AI)の進化は目覚ましく、その中心には「大規模言語モデル(LLM)」と呼ばれる技術が存在します。昨年末にはDeepSeekがアメリカ製のLLMを脅かす存在として話題になりました。そのショックは凄まじく、NVIDIAの株価が下落し、最近では同じく中国発のAI AgentのManusがDeepSeek再来と噂されていたのも記憶に新しいです。DeepSeekの特徴として、高速かつ高性能な処理を実現するために様々な工夫があります。本記事では、その中でもMixture of Experts(MoE)とMulti-Head Latent Attention(MLA)という技術について、分かりやすく解説していきます。
Transformerとは?
DeepSeekの基盤には「Transformer」と呼ばれるAIモデルの構造が使われています。これは、文章の意味を理解し、自然な文章を生成するのに優れた仕組みです。Transformerの基本構造を理解することが、以降の技術を理解する上で重要になります。
Transformerの基本構造
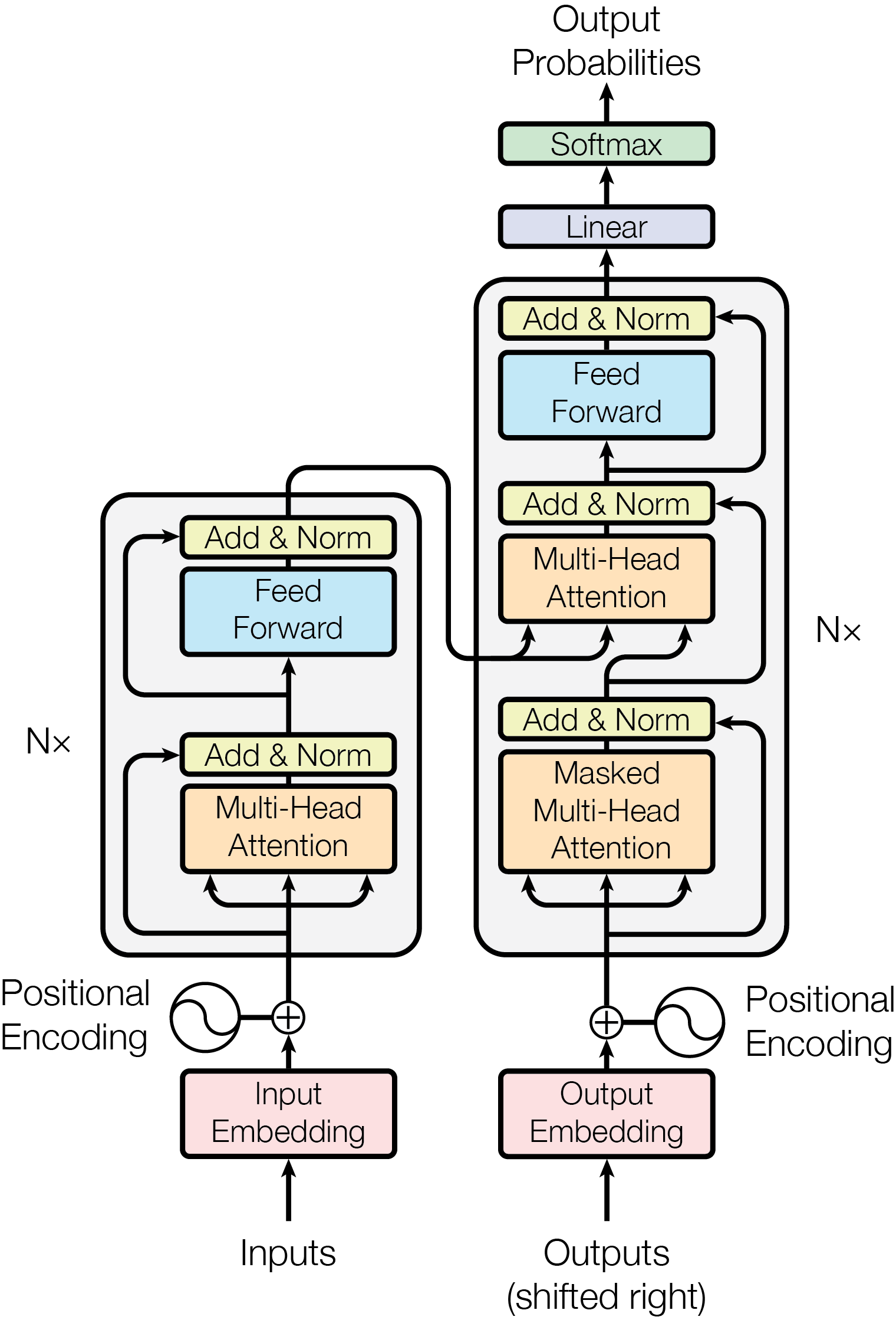
Transformerは、以下の主要なコンポーネントから構成されています。
- 埋め込み(Embedding) - 単語を数値ベクトルに変換し、AIが扱いやすい形にする。
- 位置エンコーディング(Positional Encoding) - 文章内での単語の順序を示し、文脈を正しく捉える。
- マルチヘッド・アテンション(Multi-Head Attention) - 単語同士の関係を多面的に分析し、適切な文脈を作る。
- 加算&レイヤーノーマライゼーション(Add & Layer Normalization) - 各層の出力を安定化し、学習をスムーズにする。
- フィードフォワードネットワーク(Feed Forward Network) - 各単語の情報をより深く処理し、意味を強化する。単に全結合層のこと。
Multi-Head Attention(MHA)の詳細

Transformerの中心的な技術である「自己注意機構(Self-Attention)」は、各単語が他の単語とどのように関連しているかを判断します。これを拡張したものがMulti-Head Attention(MHA)です。この章では詳しく解説していきます。
MHAでは、入力された単語の情報が複数の「ヘッド(Head)」に分かれ、それぞれ異なる視点で単語の関係を分析します。これは、例えば文章を読むときに「主語と動詞の関係」「形容詞が修飾する名詞」などを同時に考えるのと似ています。まずその中で使われているScaled Dot-Product Attentionについて見ていきます。
Scaled Dot-Product Attentionの計算は、以下の式で表されます。
Q(Query)は入力された単語を表します。Qを開くと
この計算の\(\vec{q}K^T\)に着目してみます。
つまり、この計算結果は\(\vec{q}\)と各\(\vec{k}_j\)の内積(類似度)のベクトルです。
※ \(\sqrt{d_k}\)で割るのは、次元\(d_k\)が大きい場合に内積の値が大きくなりすぎ、softmaxの勾配が消失するのを防ぐためです。
※ softmax関数により、ベクトルの要素の合計が1になり、注意の重み(割合)として扱いやすくなります。
V(Value)を
Multi-Head AttentionはこのAttention計算を複数並列で行います。
ここで、\(h\)はヘッドの数、\(W_i^Q, W_i^K, W_i^V\)は各ヘッド\(i\)のための射影行列、\(W^O\)は最終的な出力のための射影行列です。
Transformerの構造では、多くの場合、Q, K, Vとして同じ入力\(X\)(単語埋め込みと位置エンコーディングの和)を受け取るようになっています(Self-Attention)。Queryはまだしも、重要なKeyやValueも同じ\(X\)を使用しています。もし射影行列\(W_i^Q, W_i^K, W_i^V\)がなければ、同じ\(X\)をAttentionに入れてもあまり意味のある処理になりませんが、\(W\)によって入力\(X\)を異なる部分空間に射影し(値を「曲げて」)、Attentionへの入力をヘッドごとに変えてやります。これにより、入力\(X\)から、注目すべき場所(Key)や抽出するべき情報(Value)を、異なる観点(ヘッドごと)で動的に計算する構造が作られます。
このMHAの仕組みによって、Transformerは文章の意味を深く理解し、自然な文生成が可能になります。
この基本構造を押さえた上で、DeepSeek V2が導入しているMixture of Experts(MoE)やMulti-Head Latent Attention(MLA)の改良点について見ていきましょう。
Mixture of Experts(MoE)とは?
MoEの基本概念
Mixture of Experts(MoE)は、大規模なAIモデルを効率的に動作させるための技術の一つです。簡単に言うと、「たくさんの専門家(エキスパート)の中から、最適な人を選んで仕事を任せる仕組み」です。
例えば、学校の授業を思い浮かべてみましょう。あるクラスに数学が得意な先生、英語が得意な先生、歴史が得意な先生がいるとします。生徒が「数学の問題を解きたい」と思ったら、数学の先生に聞くのが最も効率的ですよね。MoEはこの考え方をAIに応用し、「どの情報処理が必要かを判断して、適切なエキスパート(計算モジュール)を選択する」仕組みになっています。
MoEの詳細
MoEは通常、Transformerブロック内のフィードフォワード層(Feed Forward Network, FFN)を複数種類用意し(これらがエキスパートに対応)、入力トークンごとに適したエキスパートを選択して使用するという方法です。一般的なMoEの構造では、入力トークンはまず「ゲート(Gating Network)」と呼ばれる小さなネットワークに入力されます。ゲートは、入力に基づいて、利用可能なエキスパートの中から、その入力処理に最も適したものをいくつか(例えば2つ)選択します。そして、選択されたエキスパートのみが活性化され、その計算結果がゲートによって算出された重みに基づいて組み合わされます。
DeepSeekにおけるMoEの特徴
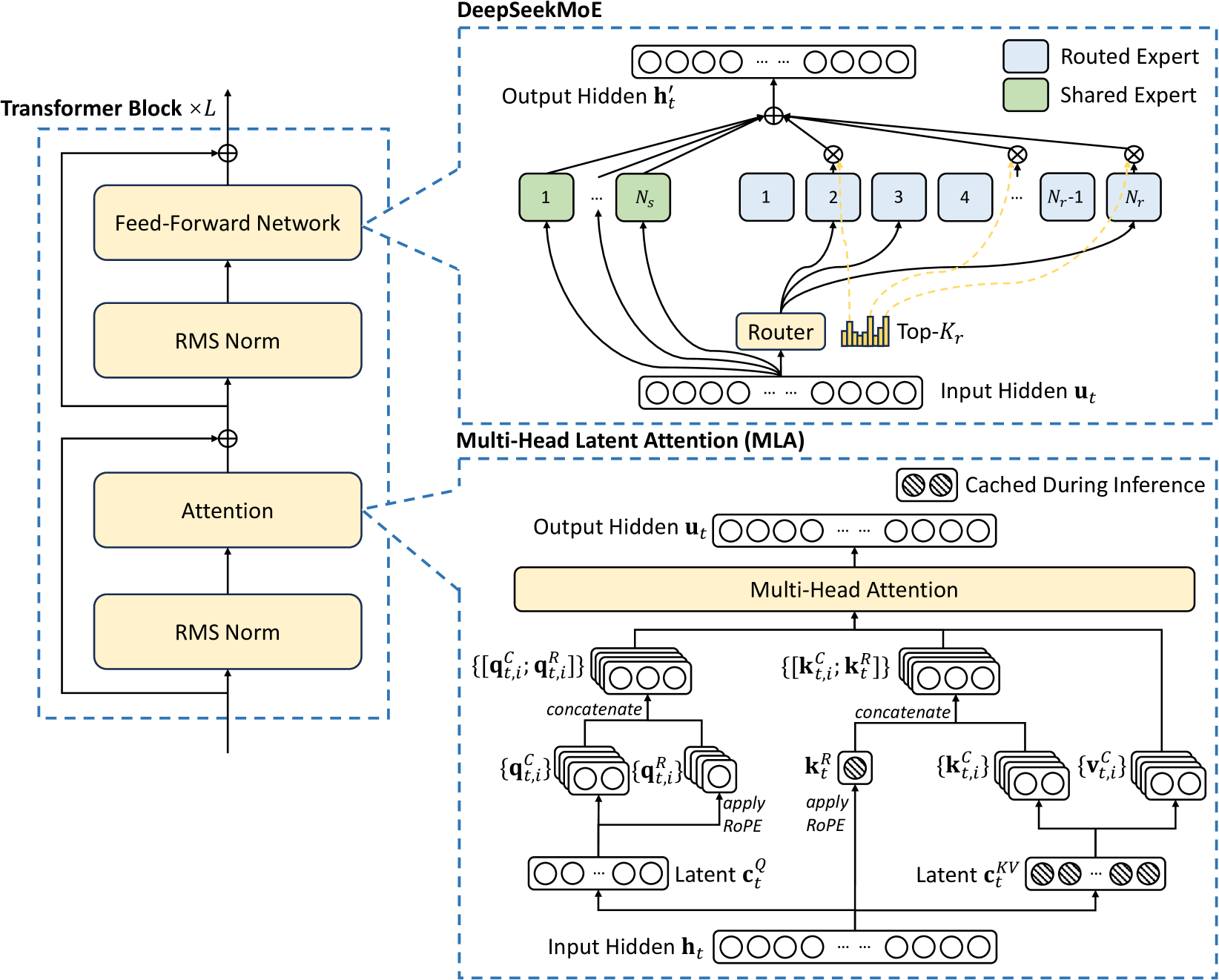
DeepSeekでは、MoEをさらに進化させるために、以下の工夫を行っていると説明されています。(注:以下の数値は元のテキストに基づいています。DeepSeek V2の公式発表とは異なる可能性がある点にご留意ください。)
- エキスパートの数を増やす - 最新バージョン(DeepSeek v3と元のテキストにある)では256のエキスパートが存在するとされる。
- 選択するエキスパートの数を増やす - 1つではなく、8つのエキスパートを選択することで柔軟な処理が可能になるとされる。
- 共有エキスパートの導入 - どの状況でも必ず選ばれる「共有エキスパート」を導入し、安定した性能を確保するとされる。
この仕組みにより、DeepSeekは「入力トークンごとに必要な計算だけを実行」することができ、モデル全体のパラメータ数は巨大でも、推論時の計算コストを抑えて効率的に動作します。
Multi-Head Latent Attention (MLA) とは?
LLMが行っている処理は次単語予測であり、基本的には今まで出力した単語(トークン)のシーケンスを入力として用いています。Multi-Head Attention(MHA)のセクションで見たように、入力\(X\)はトークン\(x_1, \dots, x_n\)に対応するベクトル列であり、これは今までに出力された(あるいは入力として与えられた)単語列を表します。この値を用いて\((n+1)\)個目の単語(トークン)を出力します。次に\((n+2)\)個目の単語を予測するときは、\(x_1, \dots, x_{n+1}\)を入力とするため、\(x_1, \dots, x_n\)の部分については原理的には再計算が必要です。
多くのLLMでは、この再計算を避けるため、\(x_1, \dots, x_n\)の処理中に計算されたKey(K)とValue(V)のベクトルをメモリにキャッシュしておき、次のステップでは新しいトークン\(x_{n+1}\)に対応するKとVだけを計算し、キャッシュに追加します(KVキャッシュ)。ここで、MHAはLLMの中で複数箇所(多くの層、多くのヘッド)で使用されていることを思い出してください。例えば、DeepSeek V2のような大規模モデルでは、合計で数千から一万以上のAttentionヘッドが存在します。このすべてのヘッドのKとVの値をメモリにキャッシュする場合、シーケンス長(トークン数)が長くなるにつれてメモリ消費量が膨大になります。元のテキストによれば、トークンごとに4MBを消費すると仮定すると、10万トークンのシーケンスを処理するためには400GBものキャッシュが必要になる、と試算されています。
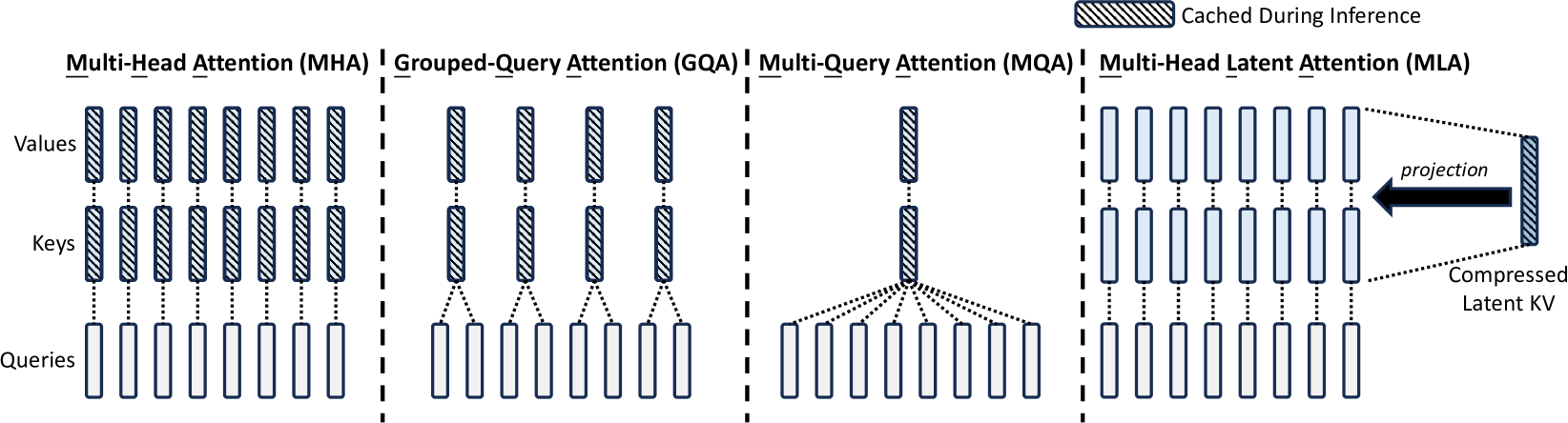
Multi-Query Attention (MQA) と Grouped-Query Attention (GQA)
このKVキャッシュ問題を緩和するために考案されたのがMulti-Query Attention (MQA)です。MQAでは、全てのAttentionヘッドでKeyとValueの射影行列(\(W^K, W^V\))および計算されたK, Vベクトルを共有します。つまり、ヘッドごとに異なるQuery(\(Q_i = XW_i^Q\))は持ちますが、Key(\(K = XW^K\))とValue(\(V = XW^V\))は共通の一つだけを使います。これにより、キャッシュする必要があるKとVはヘッド数に依らなくなり、大幅にメモリ消費量を削減でき31 KB/tokenになります。これによりキャッシュサイズは劇的に削減されますが、一方で、全てのヘッドが同じK/Vを参照するため、モデルの表現力が低下し、性能が悪化するという欠点がありました。
そこで次に考えられたのがGrouped-Query Attention (GQA)です。GQAはMHAとMQAの中間的な手法で、複数のヘッドをグループにまとめ、グループ内でKeyとValueを共有します。例えば、12個のヘッドを3つのグループに分けた場合、3セットのKとVだけを用意すればよくなります。これにより、MQAよりも性能低下を抑えつつ、MHAよりもメモリ効率を改善することができます。しかし、特に非常に長いシーケンスを扱う場合など、この方法でもキャッシュサイズや性能のトレードオフが課題となる場合があります。
Multi-Head Latent Attention (MLA)
DeepSeekでは、このKVキャッシュ問題に対処するさらなる方法としてMulti-Head Latent Attention(MLA)を採用したと説明されています。まず、MHAの式を(\(Q=K=V=X\)の場合で)再確認します。
MLAでは、「Latent(潜在変数)」\(L\)というものを使用します。元のテキストの説明によれば、このLatent \(L\)は、\(K_i = LW_i^{ku}\) となり、また \(V_i = LW_i^{vu}\) となるような中間表現であるとされています。さらに、\(L\)は入力\(X\)から \(L = XW^U\) のように生成されるとも示唆されています(\(K_i = LW_i^{ku} = XW^U W_i^{ku}\)という式より)。
このようなLatent \(L\)を用意し、もしQueryも \(Q_i = LW_i^{qu}\) のように \(L\) から生成されると仮定すると、Attentionの計算は以下のようになると考えられます。
ここからさらに式変形が進み、
のような形になります。
このMLAの核心は、\(X\)から低次元のLatent \(L\)を生成し、KとV(場合によってはQも)をこの共有の\(L\)から各ヘッドごとに小さな射影で作ることで、パラメータ数や計算量、そして特にKVキャッシュのサイズを削減することにあると考えられます。元のテキストによれば、この方法でKVキャッシュサイズをMHAの約1/57に削減でき、さらにLatent \(L\)の次元を圧縮することで一層の削減が可能とされています。
RoPEとは?
DeepSeekのMLAにはRoPE (Rotary Positional Embedding)が使用されています。RoPEは、Transformerにおける位置エンコーディング(Positional Encoding)の手法の一つです。LLMでは、トークンがシーケンス内のどの位置にあるかという情報をベクトル表現に埋め込む必要があります。RoPEは、トークンの埋め込みベクトルを、その絶対位置に応じて「回転」させることで位置情報を付与します。この方式は、特にAttention計算において、トークン間の相対的な位置関係を自然に捉えることができるという利点があり、絶対位置エンコーディングと相対位置エンコーディングの長所を兼ね備えているとされています。MLAの文脈でRoPEが使われる場合、通常、QueryベクトルとKeyベクトルに位置情報をRoPEで付与してからAttention計算を行います。
まとめ
本記事では、DeepSeekの技術の中でも特に重要なMixture of Experts(MoE)とMulti-Head Latent Attention (MLA)について解説しました。
- MoEは、多数のエキスパート(計算モジュール)の中から入力に応じて最適なものを選択的に利用することで、モデルの巨大化と計算効率を両立させる技術です。
- MLAは、Attention計算におけるKeyとValueの表現にLatent(潜在変数)という中間層を導入することで、KVキャッシュのメモリ消費量を大幅に削減し、特に長いシーケンスの処理を効率化する技術です。
これらの技術によって、DeepSeekは高性能かつ効率的な動作を可能にしていると考えられます。次回はDeepSeekのコア技術である並列処理(Parallel Processing)について詳しく解説していきます!