AI Agentのさまざまなサービスとその使い分け
2025/01/26 AI AI Agent Dify LangGraph LLM
近年のAI技術の進歩は目覚ましく、特に2024年後半からは、AIエージェントという新たな概念が急速に注目を集めています。この記事では、各種Agentサービスの紹介やAgentとWorkflowの使い分けについて解説します。
AI Agentのさまざまなサービスとその使い分け
1. はじめに:AIエージェントの隆盛
近年のAI技術の進歩は目覚ましく、特に2024年後半からは、AIエージェントという新たな概念が急速に注目を集めています。Microsoft、Salesforce、Googleといったテクノロジー業界の巨人たちが、相次いでAIエージェントサービスを発表し、市場はまさに過熱状態にあります。これらの企業は、それぞれが開発したAIエージェントを、自社の製品やサービスに統合することで、より高度な自動化とインテリジェンスを提供しようと競い合っています。例えば、MicrosoftはCopilot Agentsを、SalesforceはAgentforceを、そしてGoogleはProject Marinerを発表し、これらのサービスは、ビジネスプロセスの自動化、顧客対応の効率化、そして複雑なデータ分析など、多岐にわたる分野での活用が期待されています。
しかしながら、これらのサービスが宣伝する「自律性」や「汎用性」といった魅力的なキーワードの裏側には、注意すべき側面も存在します。多くのAIエージェントサービスは、実際には高度なツール連携や自動化にとどまっており、真の自律性を持つには至っていないのが現状です。AIエージェントは、特定のタスクを自動化する能力は高いものの、完全に人間の介入なしに複雑な問題を解決できるわけではありません。また、その複雑さから、導入や運用には高度な専門知識が必要となるケースも少なくありません。
本記事では、このAIエージェントの過熱した市場を冷静に見つめ、主要なAIエージェントサービスを技術的な側面から徹底的に比較分析します。それぞれのサービスの強みと弱みを明らかにし、本当にAIエージェントが必要とされる場面、そしてワークフローで十分な場面を見極めるための判断基準を提示します。さらに、過剰なエージェント依存に警鐘を鳴らし、AIエージェントと従来のワークフローを適切に使い分けるための戦略を提言します。読者の皆様が、AIエージェントの可能性を最大限に引き出しつつ、リスクを最小限に抑え、自社のビジネスニーズに最適なソリューションを選択するための羅針盤となることを目指します。
AI技術の進歩は常に変化しており、その速度はますます加速しています。そのため、最新の動向を把握し、常に批判的な視点を持つことが重要です。本記事が、読者の皆様がAI技術を正しく理解し、自社のビジネスに効果的に活用するための一助となることを願っています。
2. 主要AIエージェントサービス徹底比較
AIエージェントサービスは、その目的や機能によって多岐にわたります。ここでは、主要なサービスをいくつかのカテゴリに分類し、それぞれの特徴と具体的な使用例、そしてメリットとデメリットについて詳しく解説します。読者の皆様が、自社のニーズに最も適したサービスを見つけ出すための情報を提供することを目指します。
2-1. 汎用マルチエージェント
汎用マルチエージェントは、特定のタスクに限定されず、幅広い業務をサポートできるAIエージェントです。これらのエージェントは、テキスト処理、データ分析、Web検索、タスク管理など、さまざまな機能を統合しており、複雑な業務プロセスを自動化するために活用されます。
- Microsoft Magentic-One: Microsoftが提供するMagentic-Oneは、汎用AIエージェントとして、さまざまなタスクに対応できるように設計されています。このエージェントは、ユーザーが入力した自然言語の指示に基づいて、Web検索やデータ分析などのツールを使い、タスクを実行します。例えば、Magentic-Oneは、市場調査レポートの作成を指示された場合、Web検索で関連情報を収集し、収集した情報を分析してレポートを作成することができます。しかし、現段階では、Magentic-Oneはまだ開発途上にあり、その挙動は必ずしも安定しているとは言えません。特に、複雑なタスクや予期せぬ状況に直面した場合、適切な対応ができない場合があります。また、Webブラウジング機能も提供されていますが、エラーが発生したり、期待通りの動作をしないこともあります。Magentic-Oneの強みは、Microsoftの他のサービスとの統合が容易である点です。例えば、Azureとの統合により、エンタープライズ環境での利用を想定した拡張性やセキュリティ機能が提供されます。これにより、大規模な企業でも安心して利用できる可能性があります。しかし、現状では、まだ開発段階であるため、完全に自律的な動作には至っておらず、今後の開発に期待が寄せられます。Microsoftは、Magentic-Oneの改善を継続的に行い、より信頼性の高いAIエージェントを提供することを目指しています。
- CrewAI: CrewAIは、700以上のアプリ連携とノーコードUIを提供している点が特徴です。このエージェントは、Zoom会議の自動議事録生成、メールの自動返信、SNSの投稿スケジュール管理など、さまざまなタスクを自動化することができます。例えば、Zoom会議の自動議事録生成では、会議の音声データを解析し、テキスト化して議事録を作成することができます。また、Slackとの連携により、会議の議事録を共有することも可能です。CrewAIの最大の利点は、複雑なプログラミングの知識がなくても、さまざまな業務を自動化できる点です。ノーコードUIにより、直感的な操作でエージェントを設定し、さまざまなツールやサービスと連携させることができます。しかし、CrewAIは複数エージェントを連携させてタスクを実行する際に、コストが増大する傾向があります。複数のエージェントが連携して複雑なタスクを処理する際には、それだけ多くの計算資源が必要となり、その結果としてコストが増加するのです。また、複数エージェントが連携することで、システムの複雑性が増し、デバッグやメンテナンスが難しくなる可能性もあります。そのため、CrewAIを利用する際には、コストと複雑性を考慮した上で、慎重に導入を検討する必要があります。

.svg)
2-2. コーディング特化型
コーディング特化型AIエージェントは、ソフトウェア開発に特化したAIエージェントです。これらのエージェントは、コードの生成、修正、テスト、デバッグなど、プログラミングの様々な側面をサポートし、開発者の生産性向上に貢献します。
- Replit Agent: Replit Agentは、プログラミングに特化しており、チャットボットとの会話を通じて、本格的なシステムを開発できる点が大きな特徴です。このエージェントは、自然言語で指示された内容を解釈し、対応するコードを自動的に生成します。例えば、「Web APIを作成して、ユーザーデータを管理する」といった指示を出すと、Replit Agentは必要なコードを生成し、データベースの接続、APIのエンドポイントの作成、データの検証など、必要な処理を自動的に行ってくれます。さらに、コードの生成だけでなく、修正や実行も自律的に行い、エラーが発生した場合には、その原因を分析し、自己修正を試みる機能も備えています。これは、開発者がエラーに費やす時間を大幅に削減し、開発プロセスの効率化に貢献します。Replit Agentは、特にPythonの扱いが得意であり、バックエンドシステムの開発に非常に適しています。Pythonの豊富なライブラリを活用し、WebアプリケーションやAPIの開発を効率的に行うことができます。さらに、完成したファイルをダウンロードすることも可能で、ローカル環境での開発や他のプロジェクトへの組み込みも容易に行えます。Replit Agentは、プログラミングの知識がある開発者だけでなく、プログラミング初心者にとっても非常に便利なツールです。Replit Agentの利用により、プログラミングの学習コストを下げ、より簡単にソフトウェア開発を始めることができるでしょう。
- Cline(VS Code拡張機能): Clineは、VS Codeの拡張機能として提供され、最新のLLMを活用してコードの生成や修正を支援するツールです。Clineは、Open Routerなどのサービスを通じて、Claude 3.5 Sonnetなどの高性能な言語モデルを利用することができます。これにより、より高度なコード生成やコードの品質向上が期待できます。Clineの最大の特徴は、コードの修正や改善の「提案」に特化している点です。このツールは、コードの問題点や改善点を指摘するだけでなく、具体的な修正案を提案してくれます。例えば、コードのパフォーマンスを向上させるための最適化や、バグにつながる可能性のあるコードを指摘してくれます。しかし、ClineはReplit Agentのように完全に自律的に動作するわけではありません。Clineはあくまで開発を支援するツールであり、最終的なコードの修正や判断は、開発者が行う必要があります。これは、開発者の責任と判断を尊重し、より安全な開発プロセスを構築するための設計です。APIキーを設定することで、対話形式でプログラミングを進めることができ、開発者はClineとコミュニケーションを取りながら、コードを修正したり、新しいコードを生成したりすることができます。Clineは、より高品質なコードを効率的に開発したい開発者にとって、非常に価値のあるツールとなるでしょう。
2-3. タスク自動化エージェント
タスク自動化エージェントは、特定の業務プロセスを自動化することに特化したAIエージェントです。これらのエージェントは、スケジュール管理、データ収集、レポート作成など、定型的なタスクを自動的に実行し、人間の作業負担を軽減します。
- ChatGPTタスク: ChatGPTタスクは、自然言語でスケジュール管理を行うことができるAIエージェントです。例えば、「毎週金曜に営業報告書を生成する」という指示を出すと、ChatGPTタスクは、そのスケジュールに従ってレポートを生成します。ChatGPTタスクは、自然言語でタスクを保存することができるため、特別なプログラミングの知識がなくても、簡単にタスクを自動化することができます。また、リマインダー機能や通知機能も備えているため、タスクの実行漏れを防ぐことができます。しかし、ChatGPTタスクは、ブラウザ操作などの複雑なタスクを自動化するには、外部連携が必要となる場合があります。例えば、特定のWebサイトからデータを収集するタスクを自動化するには、外部のAPIやツールと連携する必要があります。そのため、ChatGPTタスクは、複雑なタスクを自動化するためには、他のツールやサービスとの連携が不可欠です。それでも、簡単なタスクの自動化には非常に便利であり、日々の業務の効率化に貢献します。
- Anthropic Computer Use: AnthropicのComputer Useは、コンピュータの操作を自動化することに特化したAIエージェントです。このエージェントは、ユーザーが指示した内容に基づいて、Web検索、情報転記、ファイル操作など、さまざまなタスクを自律的に実行します。例えば、「GoogleスプレッドシートにWebサイトから特定のデータを転記する」というタスクを指示すると、Computer UseはWebサイトからデータを収集し、スプレッドシートに自動的に入力します。この機能は、これまで人間が手作業で行っていた煩雑な作業を自動化することができるため、業務効率を大幅に向上させることができます。Anthropic Computer Useは、従来のRPAツールを置き換える可能性も示唆されており、多くの企業がその導入を検討しています。RPAツールは、特定のアプリケーションやシステムに依存するため、変更やアップデートに時間がかかるという課題がありましたが、Anthropic Computer Useは、LLMの柔軟性を活用することで、より幅広いタスクに対応できます。また、学習能力も備えているため、時間の経過とともに、そのパフォーマンスは向上していきます。しかし、Anthropic Computer Useは、まだ開発段階であり、エラーが発生する可能性があるため、導入には慎重な検討が必要です。
2-4. 検索エンジン連携型
検索エンジン連携型AIエージェントは、Web検索機能とAIの機能を組み合わせた、より高度な検索ツールです。これらのエージェントは、ユーザーの曖昧なクエリから最適な情報を探し出し、ユーザーが求める情報をより迅速かつ正確に提供することを目指しています。
- Genspark vs Perplexity AI: GensparkとPerplexity AIは、どちらもAIエージェントエンジンを搭載した検索ツールですが、それぞれ異なるアプローチを採用しています。Gensparkは、並列検索を行い、複数の視点から情報を収集し、各タスクにおいて言語モデルで要約を生成するため、文章の質が高い傾向があります。Gensparkは、ユーザーの検索クエリをより深く理解し、関連性の高い情報を収集するために、動的に検索クエリを最適化します。また、複数の検索結果を統合して、より包括的な情報を提供するように設計されています。一方、Perplexity AIは、タスクを分解し、複数の検索を同時に実行して情報を収集します。Perplexity AIの強みは、回答速度と情報源の透明性です。Perplexity AIは、ユーザーの質問に対して直接的な回答を生成するだけでなく、その回答の根拠となる情報源も提示します。これにより、ユーザーは回答の信頼性を確認することができます。Perplexity AIは、各ステップで要約を生成しないため、文章の質はGensparkに劣る場合がありますが、迅速な情報収集と回答の透明性を重視するユーザーには最適です。GensparkとPerplexity AIのどちらを選択するかは、ユーザーのニーズによって異なります。文章の質を重視する場合はGensparkを、回答速度と透明性を重視する場合はPerplexity AIを選択するとよいでしょう。
3. 技術的基盤:エージェントを支えるフレームワーク
AIエージェントを構築するためには、高度な技術とそれを支えるフレームワークが不可欠です。ここでは、AIエージェントの基盤となる主要なフレームワークについて、その仕組みと特徴を詳しく解説します。これらのフレームワークは、AIエージェントの開発を効率化し、より高度な機能を実現するために重要な役割を果たしています。
- LangGraph(LangChain): LangGraphは、LangChainライブラリの一部として提供されるフレームワークで、AIエージェントの処理フローをグラフ構造で表現することを可能にします。これにより、開発者は、より柔軟で複雑なワークフローを設計することができます。LangGraphでは、処理の各ステップをノードとして表現し、ノード間の接続をエッジとして表現します。これにより、条件分岐、並列処理、ループ処理など、さまざまな制御構造を直感的に表現することができます。例えば、LangGraphを利用して、顧客からの問い合わせを自動的に処理するエージェントを構築する場合、まず、問い合わせの種類を判別するノードを作成し、問い合わせの種類に応じて、異なる対応を行うノードを接続します。例えば、技術的な問い合わせであれば、技術サポートチームに問い合わせを転送するノードに接続し、製品に関する問い合わせであれば、製品サポートチームに問い合わせを転送するノードに接続します。LangGraphは、AIエージェントの複雑な処理フローを視覚的に表現できるため、開発の効率化だけでなく、デバッグやメンテナンスも容易になります。また、LangGraphは、様々な種類のLLMやツールを統合できるため、より高度なAIエージェントを開発することができます。例えば、Replit Agentでは、LangGraphを利用して、コードの依存関係を自動的にインストールする機能を実現しています。これにより、開発者は、コードの依存関係を手動で管理する手間を省くことができます。
- SELF-REFINE手法: SELF-REFINEは、大規模言語モデル(LLM)が自己フィードバックに基づいて、自身の出力を繰り返し改善する手法です。この手法は、人間が文章を推敲するプロセスに着想を得ており、追加の教師データや訓練を必要とせずに、単一のLLMを生成器、リファイナー、フィードバックプロバイダーとして活用します。SELF-REFINEのプロセスは、以下のステップで構成されます。まず、LLMは、与えられた入力に基づいて、初期の出力を生成します。次に、同じLLMが、生成された出力に対して、詳細なフィードバックを提供します。このフィードバックは、出力の改善点を指摘するだけでなく、具体的な改善策も提案します。例えば、コードの効率性が低い場合には、より効率的なコードの書き方を提案し、文章が不明瞭な場合には、より明確な表現を提案します。そして、LLMは、フィードバックに基づいて、初期の出力を改善します。このプロセスを、指定された回数繰り返すか、LLMが改善が不要と判断するまで繰り返します。SELF-REFINEの最大の利点は、追加の教師データや訓練を必要としない点です。これにより、さまざまなタスクに適用しやすく、コストを抑えながら、高品質な出力を得ることができます。例えば、コード最適化のタスクでは、SELF-REFINEを用いることで、GPT-4で最大13%の効率化が達成されています。また、対話応答生成のタスクでは、より自然で人間らしい応答を生成できるようになります。SELF-REFINEは、LLMの能力を最大限に引き出すための非常に強力な手法です。
- Microsoft Autogen: Microsoft Autogenは、ローカルで実行可能な分散エージェントネットワークを構築するためのフレームワークです。このフレームワークは、プライバシー保護を重視して設計されており、機密性の高いデータを扱う場合に特に有用です。Autogenでは、複数のエージェントが連携してタスクを実行することができます。各エージェントは、それぞれ異なる役割を担い、互いに協力してタスクを達成します。例えば、あるエージェントがデータを収集し、別のエージェントがデータを分析し、さらに別のエージェントがレポートを作成するといった連携が可能です。Autogenは、分散環境で動作するため、計算資源を効率的に利用することができます。また、ローカル環境で実行できるため、データのセキュリティを確保することができます。Microsoftは、Autogenを、より安全で信頼性の高いAIエージェントを開発するための基盤として位置づけています。Autogenの登場により、プライバシーに配慮した、より高度なAIエージェントの開発が可能になるでしょう。
4. AI AgentとWorkflowの使い分け
この章では、AIエージェントとワークフローという二つのアプローチを、詳細に比較検討します。それぞれの特徴、具体的な利用例、そして最適な選択基準を解説することで、読者の皆様がより深い理解を得られるように努めます。
4-1. エージェントとワークフローの定義
まず、AIエージェントとワークフローの基本的な定義から始めましょう。
- ワークフロー: ワークフローとは、LLM(大規模言語モデル)とツールが、事前に定義された手順に従って連携するシステムを指します。このアプローチは、タスクが明確に分解され、各ステップが事前に決定されている場合に有効です。ワークフローでは、LLMとツールが、あらかじめ定められた順序で処理を実行し、人間の介入を最小限に抑えながらタスクを完了します。各ステップでは、プログラムによるチェックを追加することができ、プロセスの進行状況を監視し、エラー発生時には早期に対処することができます。ワークフローは、予測可能で反復的なタスクに適しており、一貫性と信頼性を重視する際に最適な選択肢と言えるでしょう。
- エージェント: 一方、エージェントとは、LLMが自身のプロセスとツールの利用を動的に決定し、タスクを達成する方法を自律的に管理するシステムを指します。エージェントは、人間の指示を理解し、その目標を達成するために必要なステップを自律的に計画し、実行します。また、エージェントは、ツールを柔軟に利用することができ、状況に応じて、使用するツールを動的に変更することも可能です。エージェントは、予測不可能で複雑なタスクに適しており、柔軟性と創造性が求められる場合に最適な選択肢となります。
4-2. エージェントとワークフローのアーキテクチャ
次に、エージェントとワークフローのアーキテクチャについて詳しく見ていきましょう。
- ワークフローのアーキテクチャ: ワークフローは、通常、一連のステップで構成されています。各ステップは、LLMやツールによって実行されるタスクに対応しており、これらのステップは、事前に定義された順序に従って実行されます。ワークフローのアーキテクチャは、比較的単純で、理解しやすく、実装も容易です。各ステップの入出力が明確に定義されているため、システムの動作を予測しやすく、デバッグやメンテナンスも容易です。ワークフローは、複数のLLMやツールを連携させて、より複雑なタスクを実行することもできますが、事前に定義された手順に従って処理を実行するため、柔軟性が低いという欠点があります。予期せぬ状況が発生した場合、ワークフローは、適切に対応できない可能性があります。
- エージェントのアーキテクチャ: エージェントは、より複雑なアーキテクチャを持っています。エージェントは、LLMを中核として、さまざまなツールと連携してタスクを実行します。LLMは、タスクの目標を理解し、その目標を達成するために必要なステップを計画し、実行します。また、エージェントは、実行中に得られた情報を活用し、計画を修正したり、ツールを切り替えたりすることも可能です。エージェントのアーキテクチャは、柔軟性が高く、予期せぬ状況にも対応することができますが、複雑であり、理解しにくく、実装も難しいという欠点があります。また、エージェントは、自律的に処理を実行するため、システムの動作を予測しにくく、デバッグやメンテナンスも難しい場合があります。
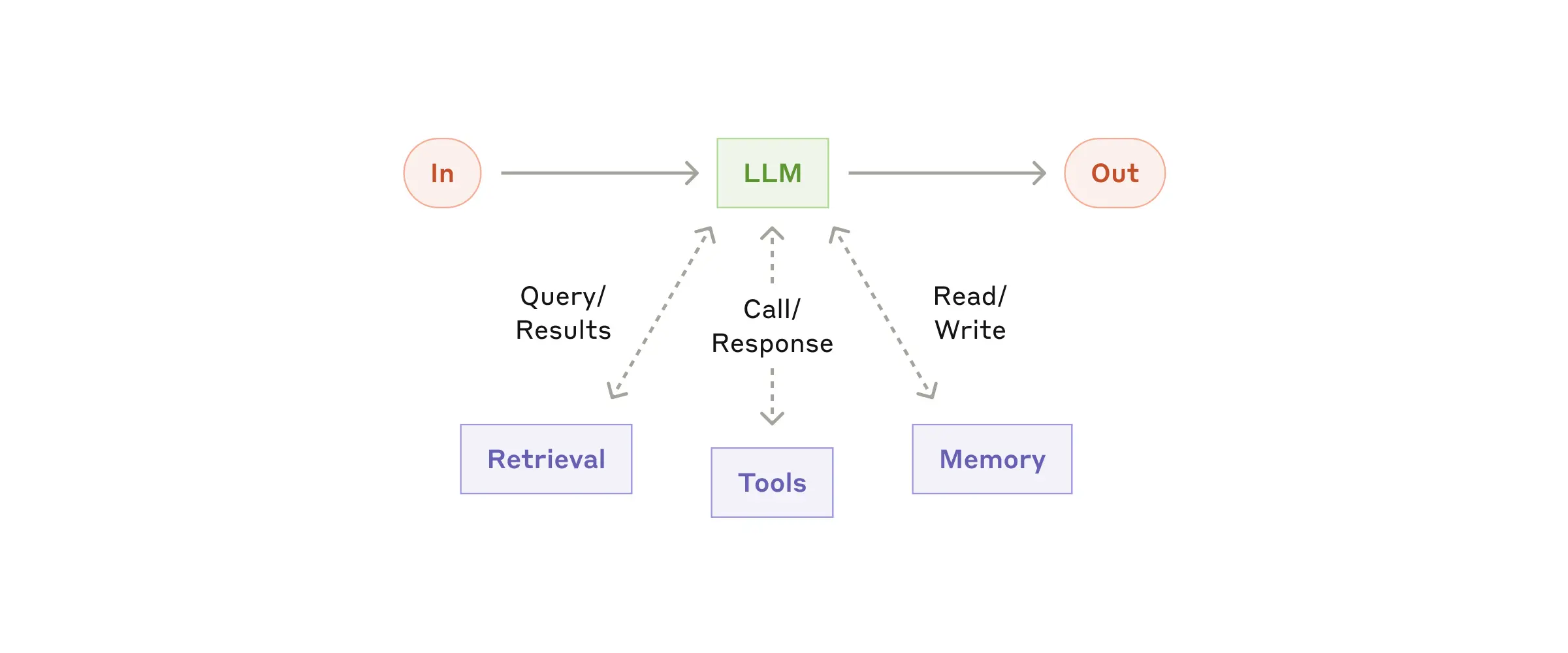
4-3. ワークフローの具体的な種類
ワークフローには、いくつかの異なる種類があります。以下に、代表的なものを紹介します。
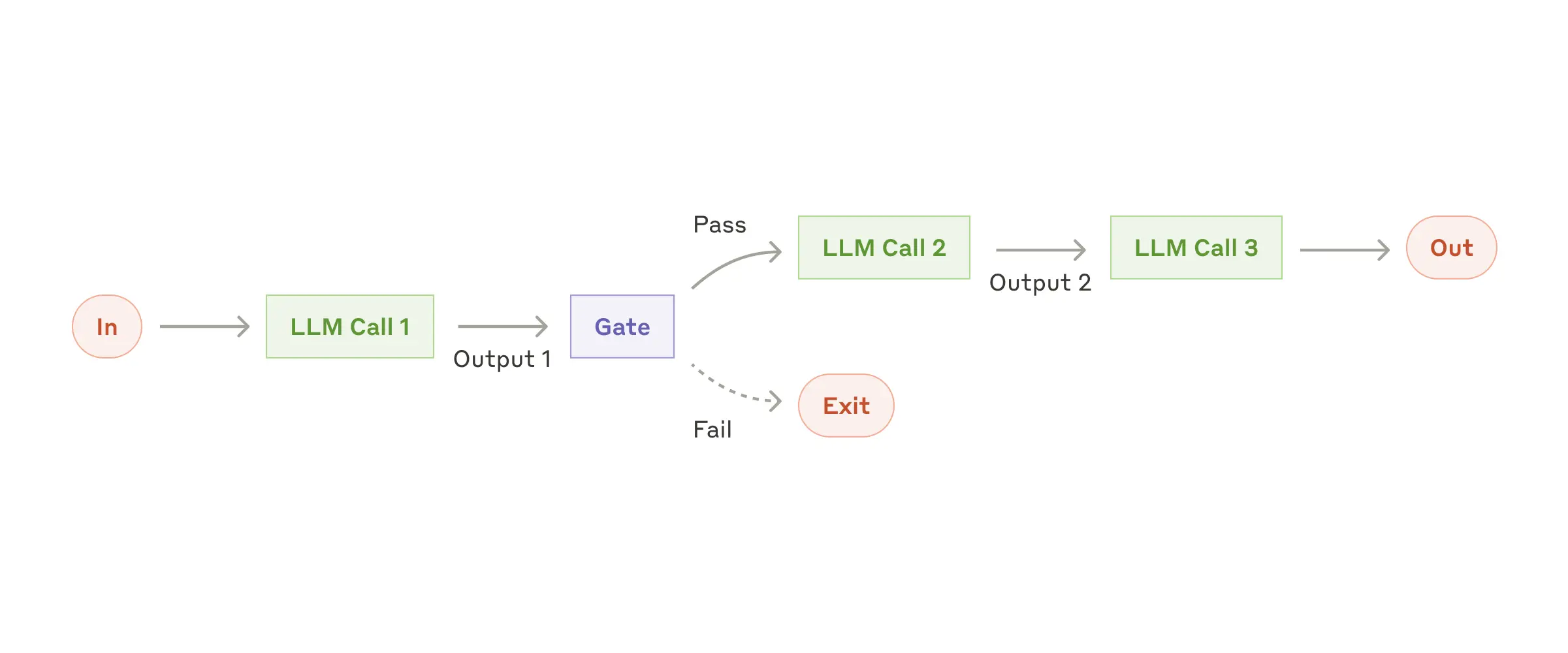
- プロンプトチェイニング: プロンプトチェイニングは、タスクを複数のステップに分割し、各ステップでLLMを呼び出して処理を実行するワークフローです。各ステップでLLMの出力を次のステップへの入力として使用することで、複雑なタスクを効率的に処理することができます。また、各ステップでは、プログラムによるチェックを追加することができ、プロセスの進行状況を監視し、エラー発生時には早期に対処することができます。プロンプトチェイニングは、タスクが明確に分割できる場合に適しており、マーケティングコピーの生成、翻訳、ドキュメントのアウトライン作成などのタスクに活用することができます。例えば、マーケティングコピーを生成した後、それを別の言語に翻訳する場合、最初にコピーを生成するLLMの呼び出しを行い、次に翻訳するLLMの呼び出しを行うというように、複数のLLM呼び出しを連鎖させます。
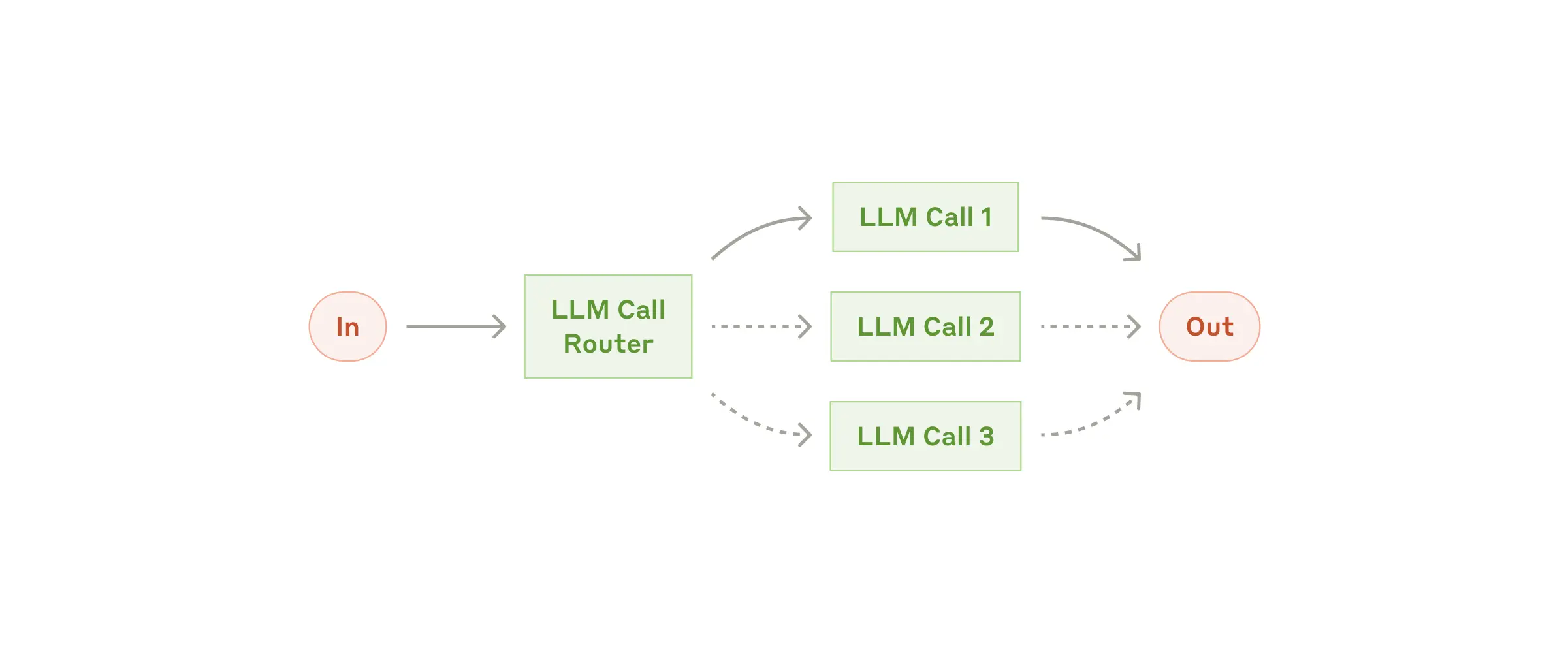
- ルーティング: ルーティングは、入力に基づいて、異なるLLMやツールにタスクを振り分けるワークフローです。ルーティングは、複数のカテゴリーを持つタスクを処理する場合に非常に有効です。ルーティングを活用することで、各カテゴリーに特化したLLMやツールを使用することができ、より適切な結果を得ることができます。例えば、顧客からの問い合わせを処理する場合、問い合わせの内容に基づいて、技術サポート、製品サポート、営業チームに振り分けることができます。これは、問い合わせ内容に応じて、「一般的な質問」「払い戻し要求」「技術的な質問」といった異なるカテゴリーに分類し、それぞれに対応したLLMやツールを利用するといった形で行われます。
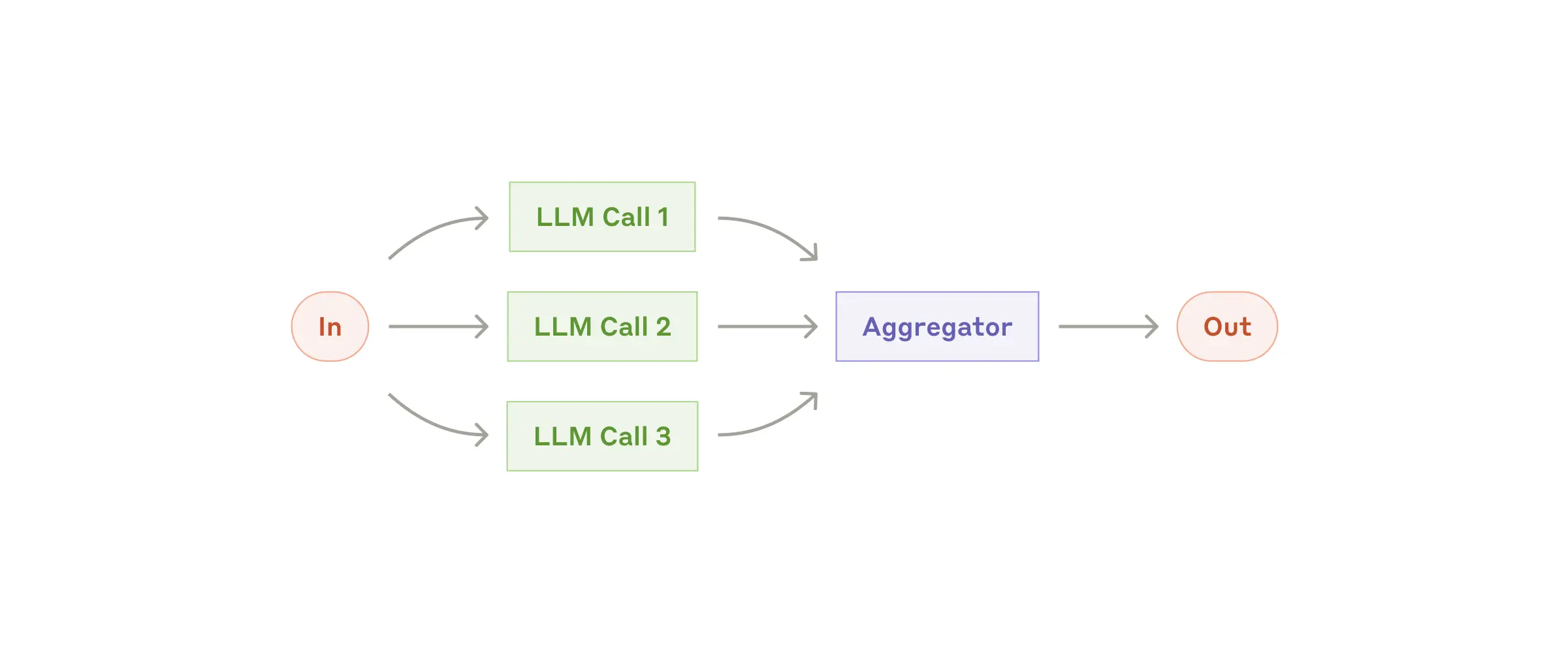
- 並列処理: 並列処理は、複数のLLMを同時に実行し、それぞれの結果を統合するワークフローです。並列処理は、複数の視点からタスクを分析したり、複数の結果を比較検討する場合に非常に有効です。並列処理を活用することで、より質の高い結果を得ることができます。並列処理には、セクショニングと投票という2つの種類があります。セクショニングは、タスクを独立したサブタスクに分割し、並列で実行する手法です。例えば、LLMの性能を評価するために、異なる側面を同時に評価することができます。投票は、同じタスクを複数回実行し、異なる結果を得て、最も適切な結果を決定する手法です。例えば、コードの脆弱性をレビューする際に、異なるプロンプトを使用して複数のレビューを行い、最も多くの指摘がある箇所を脆弱性として特定することができます。
- オーケストレーターワーカーズ: オーケストレーターワーカーズは、中央のLLMがタスクを動的に分割し、ワーカーLLMに委任し、結果を統合するワークフローです。このワークフローは、タスクが複雑で、サブタスクを事前に定義できない場合に適しています。中央のLLMは、タスクを分析し、必要なサブタスクを特定し、それぞれのサブタスクを適切なワーカーLLMに割り当てます。ワーカーLLMは、割り当てられたタスクを実行し、その結果を中央のLLMに返します。中央のLLMは、ワーカーLLMから返された結果を統合し、最終的な結果を生成します。例えば、複数のファイルに変更を加える必要があるコーディングタスクなど、タスクを分解することが難しい場合に有効です。
- 評価者-最適化者: 評価者-最適化者は、LLMが生成したレスポンスを、別のLLMが評価し、フィードバックを提供するループを持つワークフローです。評価者のLLMは、生成されたレスポンスの品質を評価し、改善点を指摘します。最適化者のLLMは、評価者からのフィードバックに基づいて、レスポンスを改善します。このプロセスを繰り返すことで、レスポンスの品質を段階的に向上させることができます。評価者-最適化者は、翻訳、文章作成、検索などのタスクに活用することができます。例えば、文学翻訳タスクにおいて、翻訳された文章を評価者LLMが評価し、ニュアンスのずれなどを指摘し、それを基に最適化者LLMが文章を修正するという形で使用されます。
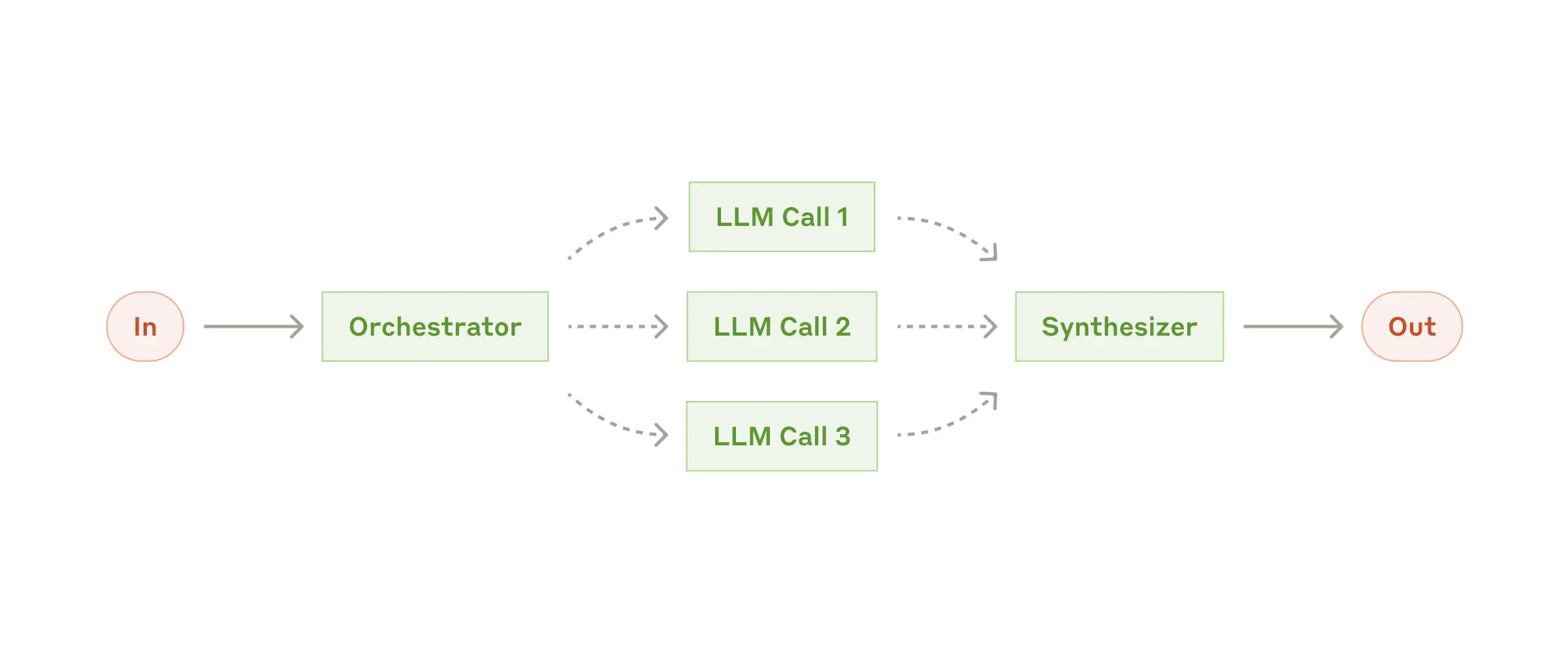
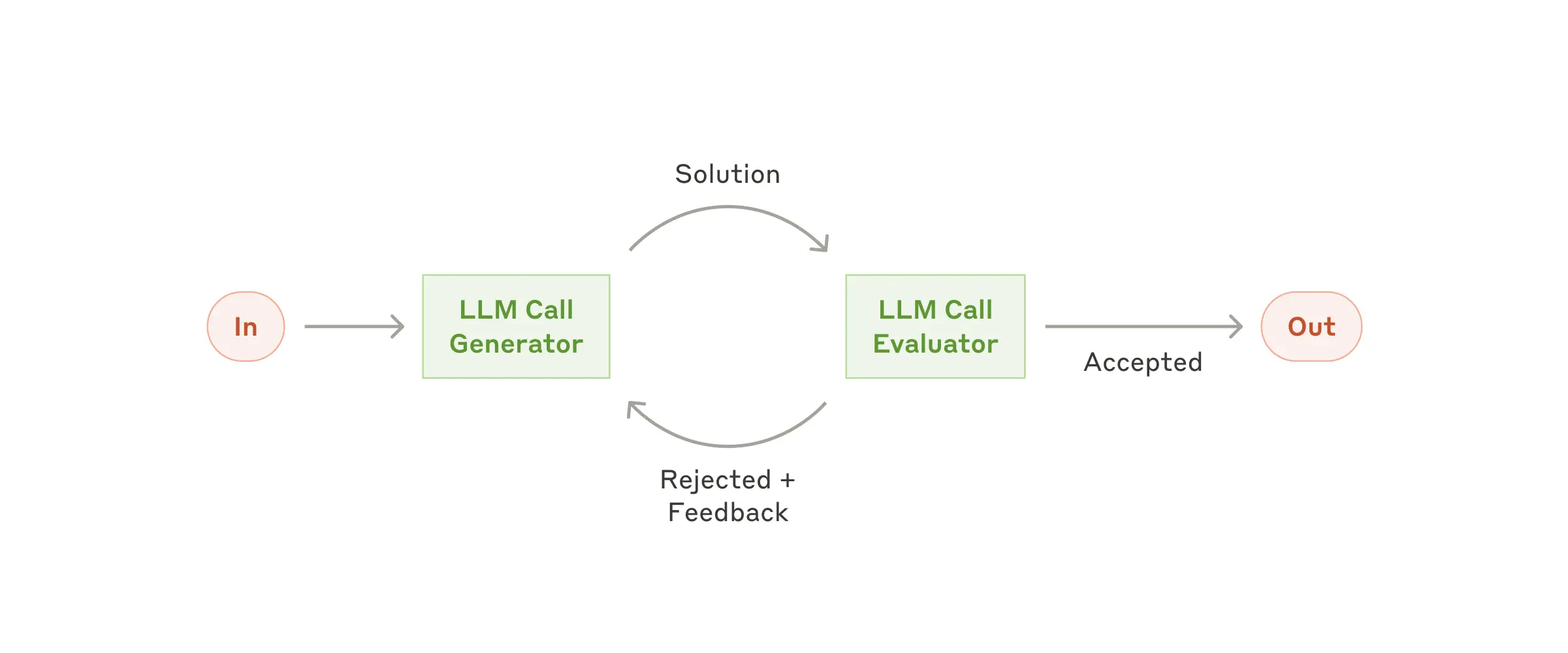
4-4. エージェントの自律性
エージェントは、自律的な行動を特徴としています。その自律性について、いくつかの側面から説明します。
- 自律的な計画と実行: エージェントは、人間の指示を理解した後、タスクを達成するために必要なステップを自律的に計画し、実行します。エージェントは、ツールを柔軟に利用することができ、状況に応じて、使用するツールを動的に変更することも可能です。タスクの実行中に得られた情報を活用し、計画を修正したり、ツールを切り替えたりすることもできます。
- 環境からのフィードバック: エージェントは、タスクの実行中に環境からフィードバックを得ることができます。例えば、コードを実行した場合、実行結果をフィードバックとして得ることができ、Web検索を行った場合、検索結果をフィードバックとして得ることができます。エージェントは、フィードバックに基づいて、自身の行動を修正し、タスクの達成度を高めることができます。
- 人間の介入の可能性: エージェントは、タスクの実行中に人間の介入を求めることができます。例えば、エージェントが、タスクの実行中に不明な点が発生した場合、人間に対して質問することができます。また、エージェントが、タスクの実行中に問題が発生した場合、人間に対応を求めることができます。エージェントは、人間との協力によって、より複雑なタスクを達成することができます。
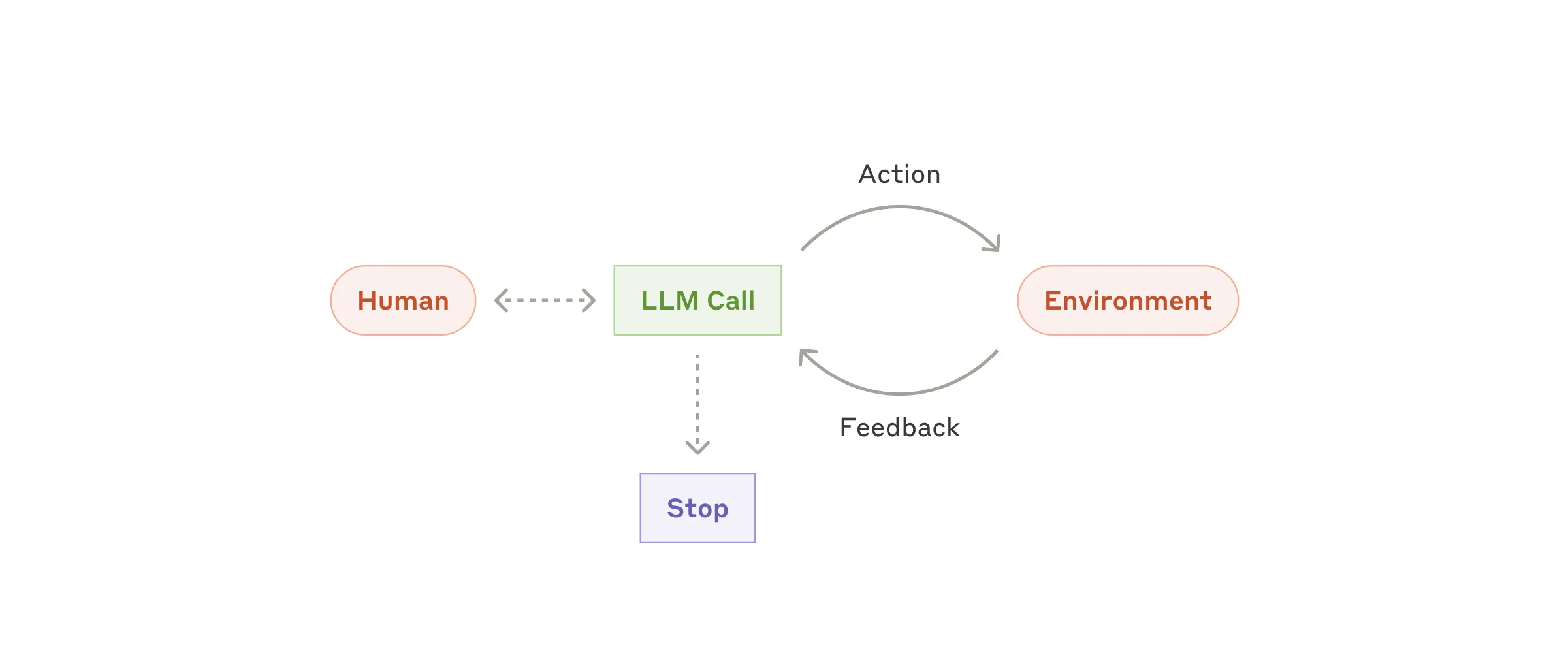
4-5. エージェントの具体的な例
エージェントの具体的な例として、以下のようなものが挙げられます。
- コード修正エージェント: コード修正エージェントは、与えられたタスクの記述に基づいて、複数のファイルを修正するタスクを実行することができます。このエージェントは、コードを分析し、変更が必要な箇所を特定し、コードを修正し、テストを実行して、コードが正しく動作することを確認します。コード修正エージェントは、ソフトウェア開発の自動化に貢献することができます。
- コンピュータ利用エージェント: コンピュータ利用エージェントは、コンピュータを操作して、さまざまなタスクを実行することができます。このエージェントは、Web検索、ファイル操作、アプリケーションの起動などのタスクを実行することができます。コンピュータ利用エージェントは、人間の手作業を代替し、生産性向上に貢献することができます。例えば、Claudeの「computer use」機能は、まさにコンピュータ利用エージェントの好例と言えるでしょう。
4-6. エージェントの適用場面と注意点
エージェントの適用場面と、利用する際に注意すべき点について解説します。
- オープンエンドな問題への適用: エージェントは、必要なステップを予測することが難しい、オープンエンドな問題に適しています。例えば、バグ修正、複雑な計画立案、創造的なタスクなどが該当します。エージェントは、自律的にタスクを実行するため、予測不可能な状況にも対応することができます。
- 信頼性: エージェントは、自律的に処理を実行するため、意思決定に対する信頼性が必要です。エージェントは、多くのターンで動作する可能性があるため、エージェントの意思決定を常に監視し、必要に応じて介入する必要があります。
- コスト: エージェントは、自律的に処理を実行するため、コストが高くなる傾向があります。エージェントは、LLMやその他の高度な技術を使用するため、計算資源が多く必要となります。そのため、エージェントを導入する際には、コストを十分に考慮する必要があります。
- エラーの可能性: エージェントは、まだ開発段階であり、エラーが発生する可能性があります。エージェントの設計においては、シンプルさ、透明性、明確なツール設計が重要です。ツールは、モデルが自然に学習できる形に近づけ、人間のコンピュータインタフェース(HCI)と同様に、エージェントとコンピュータのインターフェース(ACI)にも注力すべきです。
4-7. ワークフローとエージェントの選択基準
ワークフローとエージェントの選択基準をまとめると、以下のようになります。
| 判断基準 | ワークフロー採用 | エージェント採用 |
|---|---|---|
| タスクの予測可能性 | 高い。タスクの手順が明確で、事前に定義できる。 | 低い。タスクの手順が予測不可能で、状況に応じて変化する。 |
| 複雑性 | 低い。タスクがシンプルで、明確なステップに分解できる。 | 高い。タスクが複雑で、事前に定義された手順では対応できない。 |
| 柔軟性 | 低い。事前に定義された手順に従って処理を実行するため、状況の変化に対応するのが難しい。 | 高い。状況に応じて、自律的に計画を修正し、ツールを切り替えることができる。 |
| コスト | 低い。LLMの呼び出し回数が少なく、計算資源の消費を抑えることができる。 | 高い。LLMを頻繁に呼び出し、計算資源を多く消費するため、コストが高くなる。 |
| エラー許容度 | 低い。エラーが発生すると、重大な影響を与える可能性がある。 | 中〜高い。エラーが発生しても、リカバリーできる可能性があり、実験的なタスクに適している。 |
| 信頼性 | 高い。手順が明確で、システムの動作を予測しやすいため、高い信頼性が求められるタスクに適している。 | 低い。システムの動作を予測するのが難しく、信頼性が求められるタスクには不向き。 |
| 適用例 | 定型的なデータ分析、請求書処理、メール送信、ドキュメント生成、翻訳など、予測可能なタスク。 | 未知のバグ修正、複雑な問題解決、創造的なタスク、高度な専門知識を必要とするタスクなど、予測不可能なタスク。 |
4-8. まとめ
このセクションでは、AIエージェントとワークフローの違いを詳細に検討し、それぞれの適用場面を明らかにしました。ワークフローは、予測可能で繰り返し可能なタスクに適しており、エージェントは、予測不可能で柔軟性が求められるタスクに適しています。どちらのシステムを選択するかは、タスクの性質、コスト、エラー許容度、信頼性などの要素を考慮して決定する必要があります。
5. AI開発のときに気をつけること:使い分けに基づく設計指針
AIエージェントは、非常に魅力的な技術ですが、開発する際には、流行に流されず、慎重な設計指針を持つことが重要です。ここでは、AIエージェント開発者が注意すべき3つの原則について詳しく解説します。これらの原則を守ることで、より実用的で信頼性の高いAIエージェントを開発することができます。
- 原則1: Simple is the best: AIエージェントの開発において、最も重要な原則の一つは、シンプルさを追求することです。Anthropic社も、「API直接利用から始めよ」と提言しています。これは、複雑なフレームワークやライブラリに頼るのではなく、LLMのAPIを直接利用して、基本的な機能を実装することから始めるべきだという考え方です。単一のLLMと検索ツールで解決可能なタスクに、複数のエージェントを導入する必要はありません。複雑なシステムは、デバッグやメンテナンスが難しく、エラーが発生した場合の原因究明も困難になります。そのため、最初はシンプルな構成から始め、必要に応じて段階的に複雑化していくことが望ましいです。シンプルさを追求することで、開発と運用を効率化し、無駄な複雑さを避けることができます。また、シンプルさは、AIエージェントの信頼性を高めることにもつながります。複雑なシステムよりも、シンプルなシステムの方が、動作を予測しやすく、安定した結果を得やすいからです。シンプルさを心がけることは、AIエージェント開発の基本であり、成功への第一歩です。
- 原則2: ツール設計は「人間目線」で: AIエージェントが使用するツールは、モデルが迷わないように、明確かつ理解しやすいインターフェースで設計する必要があります。例えば、ファイル編集ツールは、絶対パスを必須とするなど、モデルが混乱しないように注意する必要があります。モデルが理解しやすいツールは、人間にとっても理解しやすく、使いやすいため、結果的に、より効率的にタスクを実行することができます。また、ツールは、モデルが自然に学習できる形に近づける必要があります。ツールを設計する際には、人間のコンピュータインタフェース(HCI)と同様に、エージェントとコンピュータのインターフェース(ACI)にも、十分な注意を払う必要があります。ACIは、モデルがツールを利用する際の使いやすさを決定する重要な要素であり、ACIが悪いと、モデルはツールをうまく利用できず、エラーが発生しやすくなります。そのため、ACIの設計には、十分な時間と労力を費やす必要があります。ツールを設計する際には、以下の点に注意してください。
- ツールの機能は明確にする。
- ツールのパラメータはわかりやすく命名する。
- ツールの使用例を記述する。
- ツールを使用する際に発生する可能性があるエラーを予測し、エラーハンドリングを実装する。
- 原則3: コストと倫理を直視: AIエージェントの利用には、コストがかかる場合があります。特に、エージェントの反復処理は、トークン消費を爆発的に増加させる可能性があります。例えば、1つのタスクあたり、$0.5のコストが、$5になることもあります。そのため、AIエージェントを導入する際には、コストを十分に考慮する必要があります。また、AIエージェントを擬人化しすぎると、ユーザーがエージェントを過信し、不適切な判断をする可能性があります。例えば、医療相談で「エージェントが診断」と表示すると、ユーザーはエージェントの診断を鵜呑みにしてしまい、医師の診察を受けない可能性があります。そのため、AIエージェントを開発する際には、倫理的な側面にも配慮し、ユーザーがAIエージェントを適切に利用できるように、十分な情報を提供する必要があります。AIエージェントの開発は、技術的な側面だけでなく、コストと倫理的な側面も考慮して行う必要があります。
6. 結論:Agentは「魔法の杖」ではない
AIエージェントは、非常に強力なツールですが、決して「魔法の杖」ではありません。AIエージェントは、自律性が必要な、事前に定義できないタスクに限定して採用すべきです。市場の過熱に惑わされず、「Workflowで済むか?」を常に自問自答する必要があります。
総括:
- AIエージェントは、自律性が必要な、予測できないタスクに限定して採用するべきです。
- 市場の過熱に惑わされず、「Workflowで済むか?」を常に自問自答することが重要です。
未来展望:
- 2025年以降、AIエージェントは、より専門的な分野に特化した「マイクロエージェント」が主流になるでしょう。例えば、医療問診に特化したAIエージェントや、法務相談に特化したAIエージェントなどが登場するでしょう。マイクロエージェントは、特定の分野に特化することで、より高度な専門知識と能力を持つことができ、より実用的なAIソリューションを提供することが期待されます。